

Kunstig intelligens (KI eller AI) synes å være alfa og omega om dagen og KI fikk sitt definitive gjennombrudd da store språkmodeller (large language models, LLMs på engelsk) ble gjort tilgjengelig for oss alle med ChatGPT i slutten av 2022.
"Prompt engineering" (prompt-konstruksjon/-design eller utforming av prompt på norsk som ChatGPT foreslår) er et annet ord man kanskje har hørt, i hvert fall de av oss som hyppig bruker verktøy som ChatGPT. Det lyses til og med ut "prompt engineer"-stillinger, med nokså absurd lønn (se både artikler fra Forbes og Business Insider).
For å definere "prompt engineering" må vi først definere hva en "prompt" er. En prompt kan oversettes til kommando, instruks, spørsmål eller ledetekst (se https://naob.no/ordbok/prompt). I KI-sammenheng kan det være et spørsmål, påstand, forespørsel, eller en beskrivelse av et problem. Det brukes i interaksjon eller samtalen med store språkmodeller som f.eks. GPT UiO. "Prompt engineering" kan sies å være kunsten å lage presise og effektive instruksjoner til samtaleroboten ("chatbot"). Et godt rammeverk for å skrive gode prompter er CLEAR prinsippene. Vær
- Konsis: korte og konsise prompter
- Logisk: strukturerte og sammenhengende prompter
- Eksplisitt: tydelig spesifisere hvordan svaret skal være
- Adaptiv: fleksibilitet og tilpasning i prompter
- Reflekterende: kontinuerlig evaluering og forbedring prompter
"Prompt engineering"-mønstre
Det finnes flere så kalte "prompt engineering"-mønstre [1] som går ut på å formulere prompter på spesifikke måter for å styre resultatet i ønsket retning. Jeg har valgt å vise to av disse i dette blogginnlegget. Den ene er "question refinement"-mønsteret, som innebærer å få hjelp av chatboten til å forbedre selve prompten.

NB: Det kan lønne seg å gjenta prompten, da svaret fra GPT UiO ikke alltid er slik man ønsker det (merk at jeg har stilt samme spørsmål sju ganger).
I dette tilfellet fikk jeg et par forslag.
![Jeg kommer til å gi deg en rekke prompter som jeg vil at du skal svare ut i fra følgende «mal»: **Tilnærmingen** Mål: [Hva du ønsker å oppnå] Nøkkelsteg: **Hvorfor denne tilnærmingen?** Begrunnelse: [forklaring på hvert trinn] **Hvordan å gjennomføre?** Implementering og kodesnutt: [Hvordan å gjennomføre hver trinn i R med kode] **Vurderinger** Drøft andre faktorer som kan påvirke denne tilnærmingen **Suksesskriterier:** Skisser hvordan du skal vurdere om tilnærmingen er vellykket. ``` 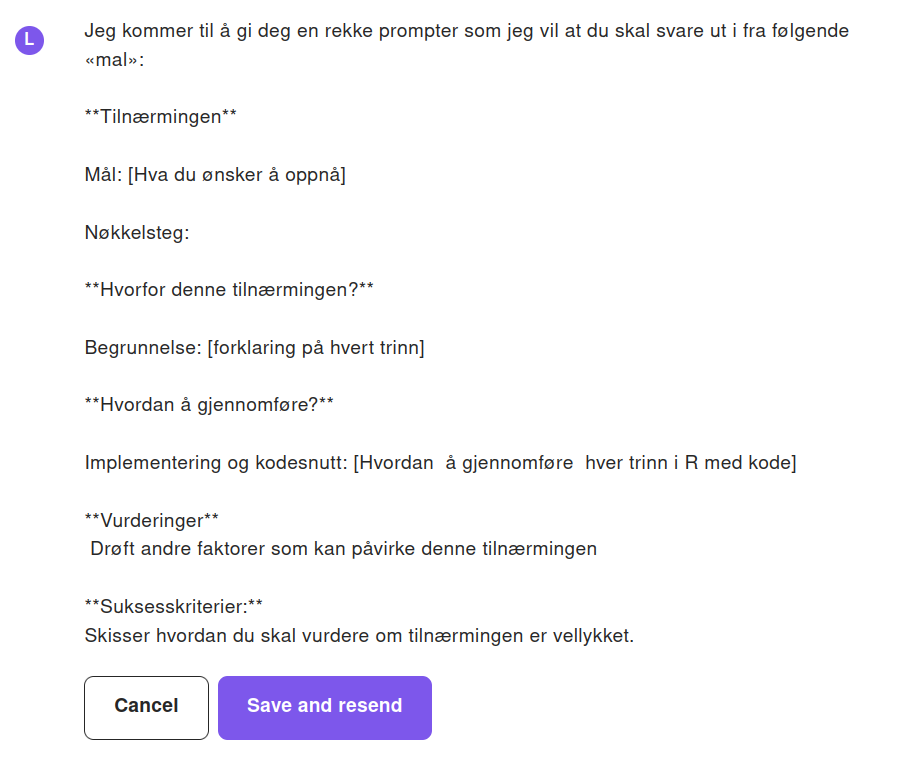 Her har jeg i tillegg slengt på markdown formattering. Deretter kan man utforme en spørring/prompt som man vil ``` Hvilken metode bør tas i bruk i R for å sammenligne to eller flere grupper med manglende data? Anta at jeg er noen som har veldig lite kunnskap om statistikk](/om/organisasjon/ffu/dht/aktiviteter/task/task-bloggen/images/question_refinement_forslag.png)
Man kan til og med spesifisere et slags innramming eller skisse GPT skal forholde seg til når den svarer.
![Jeg kommer til å gi deg en rekke prompter som jeg vil at du skal svare ut i fra følgende «mal»: **Tilnærmingen** Mål: [Hva du ønsker å oppnå] Nøkkelsteg: **Hvorfor denne tilnærmingen?** Begrunnelse: [forklaring på hvert trinn] **Hvordan å gjennomføre?** Implementering og kodesnutt: [Hvordan å gjennomføre hver trinn i R med kode] **Vurderinger** Drøft andre faktorer som kan påvirke denne tilnærmingen **Suksesskriterier:** Skisser hvordan du skal vurdere om tilnærmingen er vellykket. ```](/om/organisasjon/ffu/dht/aktiviteter/task/task-bloggen/images/template_eksempel.png)
Merk at jeg her har satt på såkalt markdown-formattering (**).
Deretter kan man følge opp med prompter man vil ha besvart:
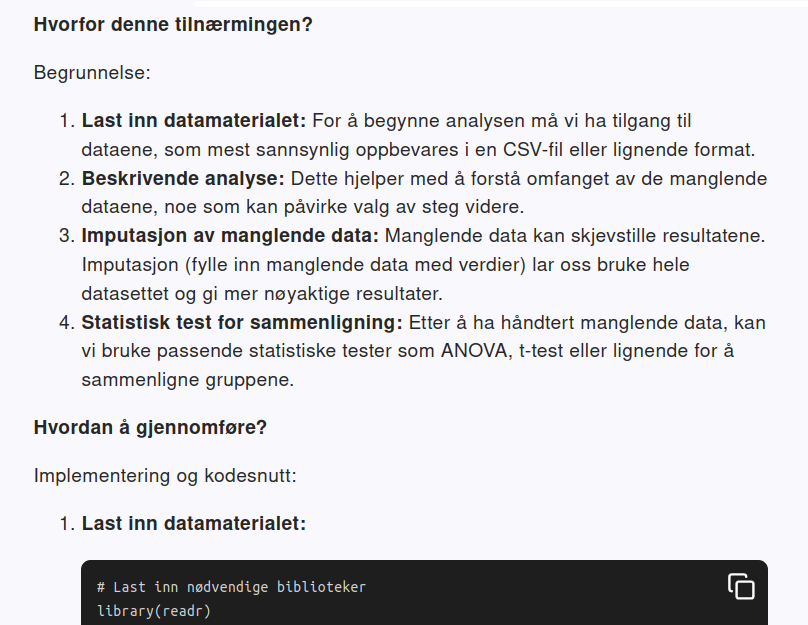
"Hvilken metode bør tas i bruk i R for å sammenligne to eller flere grupper med manglende data? Anta at jeg er noen som har veldig lite kunnskap om statistikk"
I dette tilfellet har jeg brukt "audience persona pattern", dvs. at språkmodellen svarer ut i fra at du som spør er en bestemt "persona", dvs. har en bestemt personlighet eller tilhører en gruppe mennesker tillagt visse egenskaper eller har en bestemt bakgrunn.
Her er et utdrag av svaret jeg fikk fra GPT UiO
Veien videre?
Det er mange ulike "prompt engineering"-mønstre. Hvor mange som finnes og er støttet av empiri er diskutabelt, men uansett er det å lære seg å utforme gode prompter særs nyttig i interaksjonen med språkmodeller. Vi i TASK-gruppen har gjort et forsøk på holde et slags "prompt engineering"-kurs [2] for å komme i gang med statistikk og programmering. Det er mulig vi holder noe lignende igjen, men vil da også inkludere noe om nye funksjoner i GPT UiO (ryktene tilsier at filopplastning skal være mulig ila. året)
Avslutningsvis: det er til og med snakk om måter å automatisere "prompt engineering" på (se bl.a. her, som undertegnede først fant ut av gjennom en "samtale" med GPT UiO)
[1] A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT
https://arxiv.org/pdf/2302.11382
[2] Øvrige mønstre fra kurset: "persona", "cognitive verifier", "outline expansion". I tillegg tok vi for oss "chain of thought prompting"


