
Innledning
I humaniora og samfunnsfag er det vanlig med forskningsdata bestående av tekst. Teksten kan være ren fritekst, eller være noe mer strukturert, f.eks. ha tydelige overskrifter eller integrerte metadata så som navn på forfatter, utgivelsår osv. Tekstdata kan også være i tabulær form, dvs. rutevis organisert i rader og kolonner. Selv i tabulerte data kan det være mye kvalitativ og tekstlig informasjon inni rutene. For eksempel kan data fra Twitter ha selve tweeten, altså tekstinnholdet, i en egen kolonne, mens resten av kolonnene inneholder tilhørende opplysninger.

I realfag og tekniske fag er det også vanlig med tekstlig representasjon av data. Typisk er informasjonen ganske ryddig. Likevel er det ikke alltid rett fram å hente ut data for videre analyse.
Hva er en ren tekstfil og hvordan åpner jeg en?
Med ren tekst mener vi filer som ikke inneholder noen skjult formatteringskode, annet enn linjeskift (samt "carriage return") og innrykk (<tab>). Det vil si at eksempelvis Word og Excel-dokumenter er noe helt annet. Det finnes også filer som ikke representerer tekst av noe slag. De omtales som binærfiler. Talldata lagres ofte som binærfiler, og for eksempel har R og Matlab egne binærformater.

Rene tekstfiler kan åpnes med en teksteditor. Word og andre programmer for WYSIWYG tekstbehandling bør derimot holdes langt unna tekstdata. På norsk skillervi altså, forvirrende nok, mellom teksteditor og tekstbehandler. I Windows er Notepad++ nyttig for å inspisere og behandle filer med ren tekst. På Mac kan man bruke Textedit, men pass da på å skru av WYSIWYG-funksjonaliten Rich Text Format. Andre gode teksteditorer er Emacs og Visual Studio Code.
Gjennomgang av formater
Felles for alle formatene er at de kan inspiseres og bearbeides i teksteditorer, med mindre filene er for store. Enkelte oppgaver kan løses med programmet OpenRefine, som tilbyr et relativt brukervennlig grensesnitt samt reproduserbare prosedyrer. For mer kompliserte oppgaver er skriptspråk som Python og R passende.
Fri tekst
Denne kategorien av datafiler omfatter all tekst som ikke har en allment forekommende struktur. Ofte er filendelsen .txt. For å hente ut strukturert informasjon, må vi ofte gjøre mye av jobben selv (Men det er likevel lurt å se seg rundt etter eksisterende løsninger eller kode som kan hjelpe en). Typisk ender man opp med å søke i teksten etter det man er interessert i. Av og til holder vanlig søkefunsjonalitet, som å lete etter bestemte ord. Men ofte trenger man å lete etter mer generelle mønstre, og da tyr man til noe som kalles regulære uttrykk. For eksempel kan det regulære uttrykket $Kapittel \d+: brukes til å finne hver linje som har ordet "Kapittel" først, så et mellomrom, så minst ett siffer, og så et kolon.
Mange teksteditorer har søkeverktøy innebygd. Det betyr at man kan få gjort en del arbeid på en enkelt fil. For å behandle mange filer, eller store filer, trengs gjerne skriptspråk som Python eller R.
CSV
I en vanlig data-tabell representerer hver rad et datapunkt, dvs. en samling av informasjon om en person, en gjenstand eller et fenomen, og hver kolonne en variabel, dvs. en enkeltopplysning om personen/gjenstanden/fenomenet. Variablene kan bestå av enten talldata eller tekstdata. Denne strukturen kalles en dataramme (på engelsk "data frame") i R. I SPSS og Stata kalles den enkelt og greit et datasett. Et regneark i Excel kan ha samme struktur, men også inneholde mye annet. I Python får man enkelt representert R-aktige datarammer gjennom å benytte programpakken Pandas.
En CSV-fil er en enkel tekstlig representasjon av en slik tabell.


I CSV-filen angir ofte første linje variabelnavnene (i ordnet rekkefølge), og videre kommer et nytt datapunkt på hver linje. CSV står for komma-separerte verdier fordi man ofte bruker komma til å separere hver enkelt variabel/dataverdi. Betegnelsen TSV for tab-separerte verdier forekommer også. Tekstverdier kan i CSV-filen være omsluttet av anførselstegn, noe som er nødvendig dersom tekstverdien inneholder komma (eller annet skilletegn) eller linjeskift.
CSV-filer kan importeres inn i alle slags analyseverktøy. Rstudio, Matlab, SPSS og Stata tilbyr nyttige GUIer med forhåndsvisning. Det gratis regneark-verktøyet Libreoffice Calc er hendig til kjapp inspeksjon av CSV-filer.
Prosessering av kolonner med tekstdata, for eksempel med regulære uttrykk, er mulig blant annet med Stata, Python og R. Er det snakk om kategoriske variable, slik som Gender og Genre i eksemplet over, bør man bruke analyseprogrammets egne rutiner for kategoriske variable.
JSON
Dette formatet kan romme mer kompliserte strukturer enn CSV. Eksemplet til høyre viser data som vel så gjerne kunne vært i en CSV-fil. I JSON-filen angis variabelnavnet sammen med dataverdien, i et nøkkel-verdi-par. Vi kan kalle denne strukturen en oppslagstabell. Eksemplet til venstre viser at oppslagstabellene kan nøstes: Under nøkkelen "adresse" ligger en ny JSON-struktur. I tillegg til oppslagstabeller, kan man ha lister. Under nøkkelen "telefonnumre" finner vi en liste med mindre JSON-strukturer. Det er ikke noe krav om at liste-elementene skal likne hverandre, men ofte er det sånn.

Inspeksjon av JSON-filer gjøres lettest ved å åpne dem i en nettleser som Chrome eller Firefox. Der kan nøstenivåer skjules, så man slipper å skrolle og skrolle for å få oversikt. Dersom filen ikke har linjeskift og innrykk, er ryddig visning i nettleser spesielt kjekt. Det finnes også også nyttige gratisverktøy på web som kan vise JSON-strukturer og som viser om JSON-strukturen inneholder feil, f.eks. ved at det mangler start- og sluttparenteser.
For bearbeiding av JSON-data, er skriptespråk som Python (Innebygd modul som heter json) og R (med pakken jsonlite) nyttige. Akronymet står for JavaScript Object Notation, men man trenger ikke å programmere i JavaScript for å håndtere formatet. En vanlig utfordring er å hente ut tabulær informasjon fra en mengde like JSON-strukturer (som kan foreligge i ei liste eller i separate filer). Man kan da enten forsøke å "flate ut" all nøstingen med en generisk metode (prisen man betaler er lange og kompliserte nøkkelnavn), eller å gå spesifikt etter de ønskede nøklene.
YAML
YAML-formatet likner på JSON-formatet, med nøkkel-verdi-par og lister. Også for dette formatet er bruk av programpakkeløsninger i Python, R e.l. veien å gå.
XML
XML definerer en hierarkisk, eller nøstet, struktur, i likhet med JSON. Nøklene angis inniblant tegnene < og >, i en såkalt tag.
Datainnholdet kan defineres på to måter. Enten som et tekstinnhold mellom en start-tag og en slutt-tag; I eksemplet er dette gjort mellom <filedesc> og </filedesc>. Eller som såkalte attributter inne i tagen, f.eks <bibl type="monogr">, som har attributten type. Transformasjon fra XML til JSON er derfor ikke alltid helt én-til-én. Likevel er dette ofte en grei fremgangsmåte, for eksempel ved hjelp av Python-pakken xmltodict. Ønsker man å jobbe direkte med XML-strukturen, er det også fullt mulig, og greit for å hente ut konkrete elementer.
Inspeksjon av XML-filer gjøres fint med Chome eller Firefox.


HTML
HTML brukes til å lage nettsider. Resultatet av datasanking fra Internett, er gjerne en samling med HTML-filer. I tillegg til selve tekstinnholdet kan HTML derfor inneholde alt annet en nettside har, som layout, lenker til andre nettsider, og henvisning til bilder. Syntaksen har mye til felles med XML, men ofte er innholdet i HTML lite strukturert.
I Python brukes tredjepartspakken BeautifulSoup mye for å hente ut data fra HTML. For eksempel kan man hente ut alle lenkene, hente ut alt tekstinnholdet, eller jobbe seg systematisk gjennom de ulike elementene på en side.
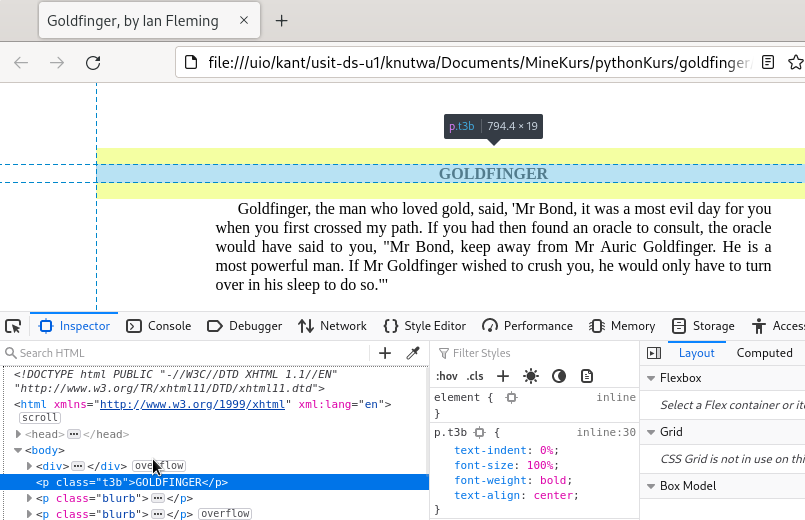
Inspeksjon/Visning av HTML-dokumenter fungerer fint i Chrome eller Firefox. Når man åpner siden, får man først opp en vanlig visning, altså slik nettsiden er ment å oppleves. Høyreklikk så på elementet man er interessert i, og velg "Undersøk" eller "Inspect". Da vil den underliggende HTML-koden bli synlig sammen med vanlig visning.
Kurs og hjelp fra TASK
Vi i TASK-teamet holder kurs i Python og R. Kurs annonseres på denne epostlista. Vi tilbyr også veiledning og assistanse innen datahåndtering gjennom kontaktpunktet datafangst@usit.uio.no. Les mer her.


