CRB-3352 omhandler et nytt, internt køsystem for å prosessere innkommende meldinger til Cerebrum. Dette er et tiltak som vil gi:
- Enklere system for å håndtere daterte endringer/forsinkede meldinger
- Mer effektiv prosessering gjennom sammenslåing av meldinger, og forhindring av dupliserte events.
- Bedre mulighet for feilhåndtering
- Bedre mulighet for feilsøking
Etter at køsystemet er implementert og tatt i bruk, vil vi også kunne fjerne dagens mer kompliserte system for håndtering av forsinkede meldinger (tiny-scheduler, Celery).
Komponenter
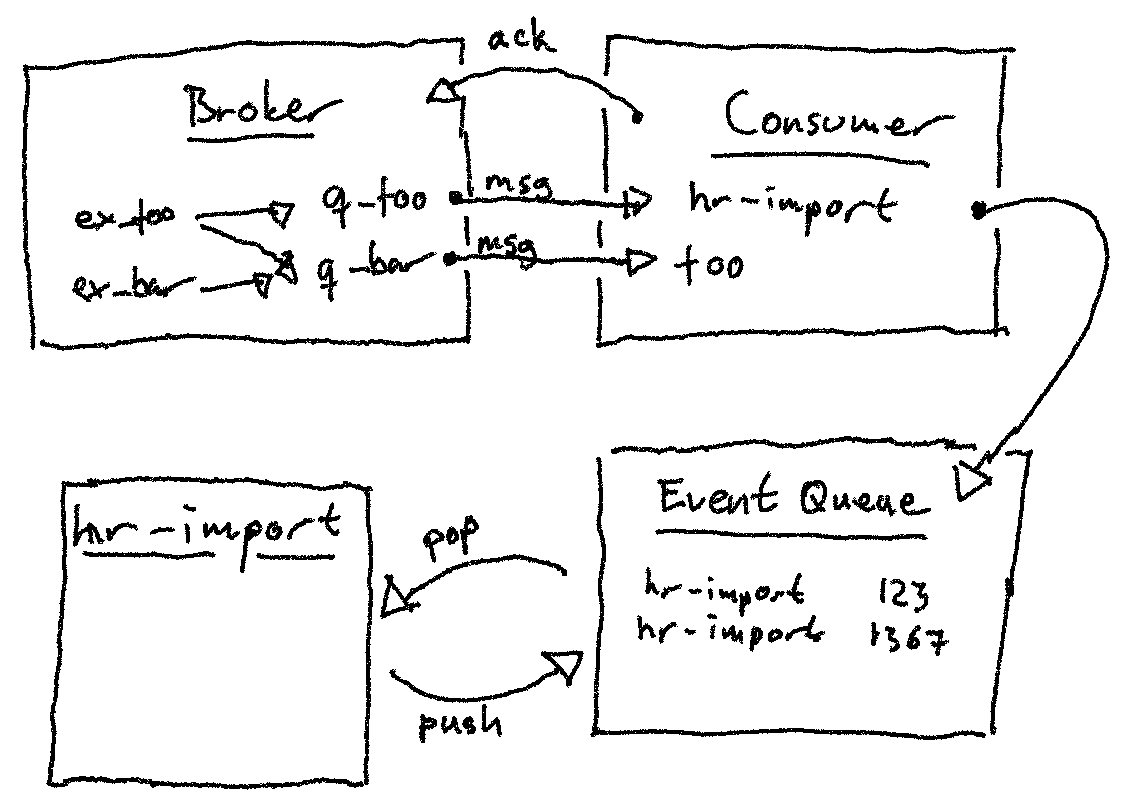
Consumer
Meldingskonsument gjøres om til en felles consumer-daemon for alle integrasjoner. Selve implementasjonen forblir mer eller mindre lik den er i dag, men i stedet for å kalle import(ansattnr), vil vi kalle noe a-la push_queue("hr-import", ansattnr).
Eventkø
En enkelt event representerer en oppgave som skal utføres. En intern eventkø i Cerebrum benyttes for å lagre slike events. Events kan deles inn i:
- Events som skal utføres umiddelbart
- Events som skal utføres på et senere tidspunkt
- Events som har feilet og skal behandles på nytt
- Events som har feilet gjentatte ganger og som skal gies opp
Køen vil fungere som et "sliding window" for å sammenstille flere samtidige events som omhandler ett og samme objekt.
Prosessering av events
Selve ansatt-importen gjøres om til en jobb som regelmessig henter og prosesserer events av en gitt type fra intern kø. Implementasjonen av ansatt-import forblir mer eller mindre lik, men kalles heller fra et script som:
- Sørger for å vedlikeholde den interne køen
- Har bedre forutsetninger for feilhåndtering og re-køing
Datamodell for kø
Den interne køen kan implementeres som en enkelt tabell med følgende felter:

- created_at (TIMESTAMP WITH TIME ZONE)
- Lagrer tidspunkt for lagring av event i kø. Benyttes til sortering (prioritering) og feilsøking.
- nbf (TIMESTAMP WITH TIME ZONE)
Lagrer tidspunkt for ønsket prosessering. Benyttes til sortering (prioritering).
TODO:
- Alternativt navn
- type (TEXT)
Event-type - identifiserer kilde og mottaker av event.
- Brukes som filter/oppslagsnøkkel for behandling
- Hver type fungerer som en egen, separat kø
- Sier noe om hva som skal prosessere event/hvordan en event skal prosesseres
F.eks. hr-import:
- type="hr-import" for ordinær oppdatering
- type="hr-import-delayed" for fremtidig oppdatering
TODO:
- Alternativt navn (event-type/event, ...)
- Deles opp i to kolonner (type, subtype), slik at vi kan ha type=hr-import, subtype=nbf?
- reference (TEXT)
Identifikator for event. For meldinger fra SAPUiO og DFØ-SAP vil referanse være ansattnummer.
TODO: Alternativt navn (identitficator/ident/id, key, ...)
- payload (JSONB)
Valgfri datastruktur. Vil typisk brukes for å lagre innhold i meldingen som er kilde til en event.
TODO: Alternativt navn (content, data, ...)
- attempts (NUMERIC)
Brukes for å telle antall forsøk på å prosessere melding.
- Nye meldinger legges inn med attempt=0
- Hvert feilede forsøk på å prosessere melding øker med 1
- Events kan re-køes med en backoff (oppdatert nbf) for hvert forsøk
- Events kan ignoreres med en cutoff-verdi (flere forsøk ignoreres)
- Kan overvåke kø for events med for mange forsøk
- reason (TEXT)
Valgfritt felt for å si noe om hvorfor en event ligger i kø
F.eks.:
- Event fra consumer/melding: message: queue=q_foo, jti=d554ea1e-1921-11eb-a414-480fcf314254
- Event fra import (sluttdato): next-change: assignment_end_date=2022-06-01
- Event feilet og skal prøves på nytt: retry: failed_at=2020-03-01 error=ValueError("foo")
Nyttig for feilsøking.
TODO:
- Alternativt navn (comment, status, ...)
Oppførsel for Consumer
Consumer setter opp køer og bindings, lytter etter meldinger i køer, og omsetter meldinger til events i intern kø.
Denne endringen gjør at meldingshåndtering skilles helt fra prosessering (f.eks. import av ansatte). Det blir en tettere loop mellom mottak av melding og ack, og oppfølging av feil blir flyttet ut av meldingskø.
Ansvar:
- Lytte etter meldinger i meldingskøer
- Oversette meldinger til events i vår nye, interne kø
- Sende ack for hver melding som blir køet
- Sende nack dersom køing feiler
Meldinger med nbf
Meldinger som inneholder et nbf-felt blir lagret direkte i kø med en egen type=<foo>-delayed. nbf i intern kø blir satt til nbf (eller tilsvarende felt) fra melding.
Meldinger uten nbf
Meldinger som ikke inneholder nbf blir lagt direkte i kø med type=<foo> og nbf=now(). Hvis det allerede finnes event med samme (type, reference) i køen, vil denne overskrives ved å oppdatere:
- created_at=now()
- nbf=now()
- attempts=0
- reason=<ny, passende kommentar>
- payload=<innhold fra ny melding>
Feilhåndtering
Dersom en melding ikke kan tolkes eller gjøres om til event, kan vi heller ikke gjøre noe særlig mer. Det bør logges en feilmelding, og selve meldingen bør ackes. Dersom dette viser seg å skje regelmessig bør vi vurdere å lage systemer eller prosesser for å bedre følge opp disse feilene.
Dersom lagring av event feiler kan dette tyde på at vi har et problem med database eller databasetransaksjon. Meldingen bør nackes, slik at vi umiddelbart forsøker på nytt.
Prosessering/import
Prosessering gjøres regelmessig gjennom en ordinær job_runner-jobb. Denne kjører hyppig, typisk annenhvert minutt, og tar unna alle events som er klar for å prosesseres.
Neste event kan typisk hentes ved utplukk:
SELECT *
FROM <queue_name>
WHERE
(type = "<foo>" OR type = "<foo>-delayed") AND
attempts < <cutoff> AND
nbf > NOW()
ORDER BY nbf ASC, created_at ASC
LIMIT 1;
Hvis utplukket ikke gir resultat er køen tom og jobben kan avsluttes. Den vil startes igjen om kort tid av job_runner.
Prosess for oppdatering
Prosessering av kø må benytte seg av to ulike databasetransaksjoner (helst transaksjon og subtransaksjon). Dette fordi vi ved feil må rulle tilbake endringer utført av import, men samtidig må oppdatere intern kø.
while True:
tx = new_transaction()
try:
event = pop_event(tx)
except Empty:
# done!
rollback(tx)
break
sub_tx = new_subtransaction(tx)
try:
needs_requeue = handle_event(sub_tx, event)
if needs_requeue:
# We found some reason to re-queue this event (e.g. near future end-date)
requeue_at, requeue_reason = needs_requeue
event.nbf = requeue_at
event.reason = format_requeue_reason(event, requeue_reason)
push_event(tx, event)
except Exception as error:
# Something went wrong, we need to retry later
rollback(sub_tx)
event.nbf = now() + calculate_backoff(event.attempts)
event.attempts += 1
event.reason = format_retry_reason(event, error)
push_event(tx, event)
else:
commit(sub_tx)
tx.commit()
I eksempelet over vil pop_event finne og fjerne en event fra køen, mens push_event vil legge til/oppdatere event i køen.
Dersom handle_event lykkes, men oppdatering av event feiler, så vil alt feile (ingen endring forekommer, det vil se ut som om event aldri har blitt rørt). Dersom handle_event feiler og resulterer i en brukket databasetransaksjon, vil vi likevel kunne oppdatere køen.
Dersom andre script endrer på køen vil enten:
- Hele transaksjonen lykkes — utenforstående endringer påvirker ikke vårt event.
- Hele transaksjonen feiler — vårt event har blitt endret på, og det vil ikke en gang se ut som om scriptet har forsøkt å prosessere eventet.
Alternativ prosess
Cerebrum-DBAL (Cerebrum.database) har ikke god støtte for subtransaksjoner. Et alternativ vil være å bruke flere urelaterte databasetransaksjoner i stedet. Noe slikt kan se ut:
while True:
with new_transaction() as get_event_tx:
try:
event = get_event(get_event_tx)
except Empty:
# done!
break
db = new_transaction()
try:
remove_event(db, event)
needs_requeue = handle_event(db, event)
if needs_requeue:
# We found some reason to re-queue this event (e.g. near future end-date)
requeue_at, requeue_reason = needs_requeue
event.nbf = requeue_at
event.reason = format_requeue_reason(event, requeue_reason)
push_event(db, event)
except Exception as error:
# Something went wrong, we need to retry later
# Must re-queue in separate tx
db.rollback()
with new_transaction() as requeue_tx:
remove_event(requeue_tx, event)
event.nbf = now() + calculate_backoff(event.attempts)
event.attempts += 1
event.reason = format_retry_reason(event, error)
push_event(requeue_tx, event)
else:
# commit changes, normal queue update
db.commit()
I eksempelet brukes get_event til å hente neste aktuelle event fra kø, og remove_event fjerner event hvis den eksisterer. Dersom kø endres mellom get_event og remove_event, så kan eventet ha blitt oppdatert eller fjernet i mellomtiden. Dette er imidlertid ikke noe stort problem:
- Dersom event oppdateres utenfra, men fjernes i script — event har til syvende og sist blitt prosessert og er vellykket.
- Dersom event fjernes utenfra, og fjernes i script — event har til syvende og sist blitt prosessert og er vellykket.
- Dersom event oppdateres utenfra og oppdateres i script — event har til syvende og sist blitt re-køet, og vil prosesseres på nytt ved et senere tidspunkt. Tidspunktet kan være ulikt i de to prosessene, og siste oppdatering vil være gjeldende. Dette er ikke ideelt, men bør ikke skape store problemer.
- Event fjernes utenfra og oppdateres i script — event har til syvende og sist blitt prosessert og er vellykket, men blir likevel re-køet og prosesseres på nytt ved et senere tidspunkt. Dette er ikke ideelt, men bør heller ikke skape store problemer.
Feilhåndtering
Dersom prosessering av event feiler, bør event re-køes med forsinket nbf. nbf bør økes for hvert forsøk, gjerne med en eksponentiell backoff.
Dersom en grense for maks antall forsøk nåes, vil event bli liggende som et slags dead letter i køen. Slike feil må uansett behandles manuelt, og det bør på sikt lages overvåking/rapport på slike events, slik at de kan følges opp.
Videre forbedringer
- Bofh-kommandoer for å sjekke tilstand i kø, søke etter events.
- Løpende statistikk fra intern kø (f.eks. gjennom statsd/graphite/grafana)
- Statistikk over prosessering (gjennom statsd/graphite/grafana)