1 Informasjonsflyt
Kommunikasjonen er enveis, i det Cerebrum får datafiler fra SAP, men rapporterer aldri noe tilbake. Datafilene kommer daglig, og data registreres i Cerebrum av flere jobber som må utføres i en viss rekkefølge. Cerebrum må utvides med egen modul for å ta vare på SAP-spesifikke utvidelser.
1.1 SAP-filer
SAP produserer tilsammen 9 filer daglig:
feide_forromr.txt lister opp forretningsområdekodene i bruk ved institusjonen.
feide_fravtx.txt lister opp fraværskodene.
feide_orgenh.txt lister opp informasjon om OU'ene i SAP og deres struktur.
Strengt tatt er det vanskelig å si i hvilken grad disse filene gjenspeiler hierarkiet slik det er i SAP. Saken er at en OU id i SAP består av to komponenter, og det overordnede stedet i denne filen er betegnet av bare den ene komponenten. Man kan anta at den andre komponenten for overordnet OU stemmer med barne-OU'en, men det er en antagelse som ikke er blitt bekreftet/avkreftet.
feide_persondata.txt lister opp informasjonen om de ansatte i SAP. Dette er som oftest den mest interessante filen.
feide_persti.txt lister opp tilsettingsinformasjonen i SAP. Altså, hvem har, eller har hatt, hvilken stilling hvor og når.
feide_perutvalg.txt lister opp informasjon om de ansattes deltagelse i ymse "utvalg" som er registrert i SAP.
feide_stillkode.txt inneholder oversikten over stillingskodene brukt internt i SAP.
feide_stilltype.txt inneholder oversikten over stillingstyper. Dette er ikke det samme som stillingskoder, selv om de ligner veldig mye hva Cerebrum angår. Stillingstypene er knyttet til de 4-sifrede statlige lønningskoder.
feide_utvalg.txt inneholder listen over utvalg som finnes og hvor folk kan være medlemmer (jfr. feide_perutvalg.txt).
Av disse filene er det kunne disse som blir brukt daglig av Cerebrum:
- feide_persti.txt
- feide_persondata.txt
- feide_perutvalg.txt
Noen av de andre filene ble opprinnelig brukt til å sette opp de nødvendige konstantene i Cerebrum, men dette er felles for alle instanser så dette er ikke nødvendig å gjøre med mindre DFØ gjør endringer i oppsettet.
2 Beskrivelse av filene
Alle filene vi får fra SAP er på omtrent samme format. Én post er én linje. Om man vil kan man tenke på én linje som én databaserad. Feltene innenfor den samme posten er adskilt med ";". Dersom ";" er en del av data, skal det escapes med backslash. Det er ikke avtalt hva som skal skje dersom backslash er en del av data.
Ikke alle felt blir brukt, og Cerebrum vil ikke merke noe dersom de feltene vi ikke ser på vil være endret på. Men det er et absolutt krav at alle linjer i en fil skal ha samme antall felt. Det antallet er fast og er hardkodet i importskriptene som leser fra de gitte filene.
Generelt identifiseres personer i SAP vha et eget SAP-personnummer, ofte kalt ansattnummer eller SAP-id. Det er dette nummeret som binder de forskjellige databitene om personen sammen. Tilsvarende identifikator finnes for OU'er, dog denne består av to deler: nummeret på organisasjonsenheten (referert av og til til som orgeh) og forretningsområdekode (4 siffer). Det finnes relativt få forretningsområder (i størrelsesorden under 10), men det finnes mange orgeh. Hverken orgeh eller forretningsområdekode er unike hver for seg, det er kun deres kombinasjon som er unik.
Mer spesifikt inneholder hver fil vi får fra SAP dette:
2.1 feide_forromr.txt
Forretningsområdekodene brukes primært til å identifisere OU'ene entydig. Det er denne koden som står som de 4 siste sifrene i fs.sted.stedkode_konv. Denne filen brukes gjerne kun under utrulling av Cerebrum, for å definere de riktige forretningsområdekodekonstantene.
Feltene er i rekkefølge (fra venstre mot høyre):
- Forretningsområdekode: 4-sifret tall
- Forretningsområdenavn: Opptil 40-tegns beskrivelse av forretningsområdekoden.
2.2 feide_fravtx.txt
Denne filen blir ikke brukt i Cerebrum i det hele tatt. Imidlertid inneholder filen:
- Fraværstype: 4-sifret tall
- Fraværstekst: Opptil 25-tegns beskrivelse
2.3 feide_orgenh.txt
Denne filen blir ikke brukt i Cerebrum. Dog, den inneholder en del data om SAP sitt syn på OU'ene, og kan potensielt brukes for konsistenssjekk med FS. Dette gjelder primært navn og hierarkiinformasjon. Filen inneholder i rekkefølge:
- orgeh: Nummeret på OU'en, et 8-sifret tall. Det satt sammen med forretningsområdekode gir en entydig identifikator av OU'en i SAP. orgeh i seg selv er ikke unik.
- Navn: Navnet på OU'en, opptil 40 tegn.
- Kostnadsstednummer: Et 10-sifret tall. Uklart hva denne er ment til å brukes til.
- Navn på kostnadssted: Opptil 40 tegn.
- Forretningsområdekode: Et 4-sifret tall.
- Kortnavn: Opptil 10 tegn.
- orgeh for overordnet OU: Følger enhetsstrukturen i SAP-hierarkiet, et 8-sifret tall.
2.4 feide_persondata.txt
Denne filen leses ved nattlig import og populerer personinformasjonen i Cerebrum. Legg merke til at denne brukes til å populere generelle persondata. Affiliationstildeling baseres på grunnlag av en annen fil.
Feltene er i rekkefølge (fra venstre mot høyre):
Ansattnummer: 8-sifret tall. Dette er en entydig nøkkel som unikt identifiserer personen i SAP.
[ubrukt] Arbeidsstedkode: 4-sifret tall. Brukes ikke av Cerebrum.
Fratredelsesdato: (!) Dato på formatet YYYYMMDD. Folk som har denne satt til en dato som nå er passert, betraktes ikke (lenger) som ansatte.
[ubrukt] Initialene: 10 tegn
Fødselsnummer: 11-sifret personnummer.
Fødselsdato: Kan være nyttig om personen har et midlertidig fødselsnummer. Består av 6 siffer på formatet YYYYMMDD (spesifikasjonen fra UiA sier 8, men det er ikke tilfellet).
Fornavn: 40 tegn.
Mellomnavn: 40 tegn. Hvis denne finnes, blir den satt sammen med fornavnet i Cerebrum.
Etternavn: 40 tegn.
[ubrukt] Sivilstatus: opptil 6 tegn.
[ubrukt] Anmeldestittel: opptil 15 tegn. Ingen ide om hva denne kan brukes til.
[ubrukt] orgeh til OU'en der personen har sin primærtilknytning. 8 siffer. Selv om denne ikke er i bruk i dag, kan det tenkes at det gir mening å gi folk tilknyttinger basert på denne.
Privattelefon: 30 tegn. Lagres i Cerebrum som kontakt-info av typen PRIVPHONE.
Interntelefon: 30 tegn. Lagres i Cerebrum som kontakt-info av typen PHONE.
Jobbmobil: 30 tegn. Lagres i Cerebrum som kontakt-info av typen MOBILE.
Privat mobil: 30 tegn. Lagres i Cerebrum som kontakt-info av typen PRIVATEMOBILE.
[ubrukt] E-post arbeid: 60 tegn.
[ubrukt] E-post privat: 60 tegn.
Bostedsadresse, C/O-delen: 60 tegn.
Bostedsadresse, gate-delen: 60 tegn.
Bostedsadresse, husnummer: 10 tegn.
Bostedsadresse, tillegg: 40 tegn. Aner ikke hva det tilllegget skal være.
Bostedsadresse, poststed: 40 tegn.
Bostedsadresse, postnummer: 10 tegn.
Bostedsadresse, land: opptil 3 tegn. Det er uklart hva slags koding som brukes her. Imidlertid defineres det konstanter i Cerebrum (en del av SAP-modulen), og denne koden (stort sett 2 bokstaver) skal kunne mappes til noe kjent vha Cerebrum sitt Constant-rammeverk.
Blir det lagt til nye koder her vil Cerebrum-importen feile for personen, og det må defineres hvilket land det er snakk om i Cerebrum.
Forretningsområdekode: 4 siffer. Dette er den andre delen av OU-nøkkelen, der personen har sin hovedtilknytning. Vi registrerer at personen er knyttet til en forretningsområdekode, men det gjøres ikke noe utover det. Hvis dette er i bruk, og denne er satt til 9999 vil personen bli ignorert fra import.
Bygningsnummer: 6 siffer. Bygningskoden til hvor personen vanligvis befinner seg.
Cerebrum kan lagre bygningsnummer som:
- Kontaktinformasjon for personen, av typen OFFICE, altså kontoradressen. Et eventuelt romnummer, registrert i neste felt, lagres som alias i kontaktfeltet i Cerebrum.
- Adresse for personen av typen street. Landskoden må være registrert i Cerebrum for at adressen skal bli importert.
For at Cerebrum skal lagre bygningsnummer må adressen til bygningskodene registreres i Cerebrum, både adresse, postnummer, poststed og land. Vi ignorerer alle udefinerte bygningskoder.
Romnummer: 6 siffer. Romnummer kan lagres samme med kontoradressen til personer. Adressen til bygget må på forhånd vere registrert i Cerebrum, se forklaring under feltet Bygningsnummer. Romnummer lagres i alias-feltet til personen sin kontaktinformasjon.
Personlig tittel: 40 tegn.
Dette feltet inneholder personlige titler, siden feltet er knyttet direkte mot en person, og ikke en stilling. Innholdet i dette feltet er likt med det som er registrert som titler i feide_stillkode.txt, som er knyttet mot personen sine stillinger i feide_persti.txt.
Telefaks: Jobbnummer. Lagres i Cerebrum som kontakt-info av typen FAX.
[ubrukt] Foretrukket språk: 2 siffer. Litt uklart hva slags kodeverk som brukes (den opprinnelige spesifikasjonen sier ISO, men nevner ikke hvilken standard).
[ubrukt] Startdato for når tilknytningen er aktiv: 6 siffer, YYYYMMDD.
[ubrukt] Sluttdato for når tilknytningen er aktiv: 6 siffer, YYYYMMDD. Hvis man skal prøve å tildele affiliations basert på denne filen, så kan disse start/slutt-datoene være nyttig å ha med.
[ubrukt] Død-status: Dette feltet angir hvorvidt personen er død. Der det er aktuelt står verdi "Død". Denne er ikke i bruk (selv om den burde være det). Det har også være diskutert hos UiA hvorvidt dette feltet skal brukes til noe annet, men foreløpig har man ikke kommet fram til noen konklusjon.
[ubrukt] Fravær/permisjon: 4-sifret kode (jfr. feide_fravtx.txt).
[ubrukt] Fraværsprosent
Reservasjonsstatus for elektroniske kataloger: Uklart hvor mange tegn. Dersom feltet er tomt, eller inneholder "Kan publiseres", skal vedkommende publiseres i elektroniske kataloger. Alle andre verdier betyr at vedkommende er reservert for publisering i slike kataloger.
Medarbeidergruppe: Dette kom som en utvidelse i 2008-05 og kan brukes for å luke ut ansatte. Populært også kalt for MEG, eventuelt MG.
Lagres i Cerebrum som et trait sap_mg.
Medarbeiderundergruppe: Dette kom som en utvidelse i 2008-05 og kan brukes for å luke ut ansatte. Populært også kalt for MUG.
Lagres i Cerebrum som et trait sap_mg.
Alle adressene blir satt sammen til noe mer passende. C/O + gate + husnummer + tillegg blir satt sammen til et felt. Poststed og postnummer har vi egne kolonner for i Cerebrum. Land må finnes blant de predefinerte konstantene.
Siden SAP opererer med egen person-id, ofte kalt ansattnummer, er det viktig å sikre at ID-informasjonen er konsistent i den grad det er mulig. Vi tillater ikke automatiske endringer av person-id (sjekken kan naturligvis kun utføres dersom fødselsnummeret forblir det samme). Vi tillater endringer i fødselsnummer, men kun dersom fødselsnummeret endres til noe som ikke finnes i Cerebrum fra før av. Fødselsnummer skal tilfredsstille sjekksumkravet - se Fødselsnummer hos Wikipedia for mer informasjon om dette. Videre er det slik at dersom fnr og ansattnummer finnes i Cerebrum, så skal de begge "peke" på samme person.
2.5 feide_persti.txt
Denne filen inneholder informasjon om ansettelsesforhold registrert i SAP. Det er SAP sitt interne personnummer (også kalt ansattnummer og SAP-id), som binder linjer i denne filen sammen med personinformasjon fra feide_persondata.txt.
Feltene er i rekkefølge:
Ansattnummer: 8 siffer. Identifiserer personen, og knytter linjen sammen med informasjon fra feide_persondata.txt.
Orgeh: 8 siffer. SAP sitt OU-nummer. Stillingen blir ignorert hvis Cerebrum ikke finner OU.
Nummer på stilling (funksjonstittel): 8 siffer. Stilling blir ignorert hvis nummer er 99999999.
Nummer på stillingskode: 8 siffer. Stillingskoden identifiserer hvilken type stilling det er snakk om. Navnet på stillingstypen er på forhånd lagret i Cerebrum. For eksempel kan stillingskoden 20001083 vere registrert med navnet "Ingeniør", mens stillingskoden 20001181 er registrert som "Senioringeniør".
Stillingskoder brukes til å registrere om tilknytningen skal vere vitenskapelig eller teknisk/administrativ. Hva hver stillingskode mappes til er registrert i Cerebrum, men kan endres per institusjon. Se mod_sap_codes.py for standard oppsett.
Cerebrum bruker også dette feltet for å lagre en person sin arbeidstittel. Ettersom en person kan inneha flere stillinger, vil importen først sjekke om personen har en hovedstilling. Om en hovedstilling ikke er definert, vil stillingen med høyest stillingsbrøk brukes. Om en person innehar flere stillinger med identisk stillingsbrøk, vil den første stillingen i fila bli brukt.
Forretningsområdekode: 4 siffer. Sammen med orgeh, gir denne oss muligheten til å identifisere OU'en. Hvis dette er i bruk, og er satt til 9999, vil stillingen bli ignorert.
Startdato: 6 siffer, YYYYMMDD. Cerebrum ignorerer stillinger med startdato mer enn 180 dager før dags dato.
Sluttdato: 6 siffer, YYYYMMDD. Cerebrum ignorerer stillinger som har passert sluttdato.
Hovedstilling/Bistilling: 1-bokstavskode (H = hovedstilling, B = bistilling).
Stillingsprosent: et flyttall mellom 0 og 100.
Det minste kravet til en gyldig tilsetting er at samtlige identifikatorer er registrert i Cerebrum. SAP-personnummeret må allerede være registrert, orgeh og forr.omr.kode må kunne finnes i sap-modulen. Stillingskoden må være registrert i Cerebrum (vi har konstantobjekter for alle lovlige stillingskoder). Stillingsprosent må være <= 100.
Det er dessverre helt ukjent for meg (ivr) hva forskjellen mellom stilling og stillingskode er i dette tilfellet. Den eneste koden vi bruker reellt sett er den som vi kan mappe om til de offisielle 4-sifrede norske statlige lønnskodene.
Den mest ubehagelige overraskelsen her er måten man tolker datoene på. Når en person slutter i en stilling, så betegner startdato ikke lenger når vedkommende har startet å jobbe, men når han har sluttet å jobbe. Imidlertid endres nummerett på stillingen til å gjenspeile den nye "vedkommende jobber ikke her lenger"-status. Vi har vært i kontakt med UiA for å få løst saken på en tilfredsstillende måte, men foreløpig har man ikke kommet fram til noe konklusjon. Per i dag tolker Cerebrumskriptene start/sluttdato for stillingen som nettopp det -- datoen når man starter og slutter i en stilling.
I tillegg ignoreres de oppføringene der forretningsområdekode er 9999. Det er slik per design. Altså, forretningsområdekode 9999 brukes som en slags merkelapp på at tilsettingen skal ignoreres. Dette brukes ikke av alle institusjoner.
2.6 feide_perutvalg.txt
Denne filen lister opp informasjon om ansattenes deltagelse i ymse verv/utvalg. Siden det ikke var i bruk hittil (2007-10-18), er det lite man kan si om filen.
- SAP-personnummer: 8 siffer.
- SAP-OU-nummer, orgeh: 8 siffer.
- Forretningsområdekode: 4 siffer.
- Utvalg: 40 tegn.
- Startdato: YYYYMMDD
- Sluttdato:, YYYYMMDD, for deltagelse i utvalget/vervet.
- Rolle i utvalget: Slike roller er definert i feide_utvalg.txt.
Det er litt uklart hvorfor man nevner OU'er her i det hele tatt. Siden modulen er i praksis ikke i bruk, er det lite poeng i å gruble over saken, men potensielt burde man kanskje binde slike roller til OU'er (det gjøres ikke i mod_sap.sql i dag).
UiA har faktisk et par utvalg definert, men feide_perutvalg.txt er alltid tom.
2.7 feide_stillkode.txt
Inneholder oversikten over stillingskodene brukt internt i SAP. Hver tilsetting får en ny kode (enda det er snakk om samme type stilling, samme tittel, osv). Nøyaktig hva denne brukes til er vanskelig å si. Vi bruker ikke denne til noe som helst.
Feltene i hver linje i filen:
- Nummeret på stillingskoden: 8 siffer. Antageligvis er alle sammen unike.
- Tekstlig beskrivelse: 40 tegn. Typisk tittel. For noen også den 4-sifrede statlige lønnskode i tillegg.
2.8 feide_stilltype.txt
Inneholder oversikten over stillingstyper. Disse kan sammenlignes med de 4-sifrede statlige lønningskoder. Vi bruker denne filen for å definere alle de kjente stillingstypene (for å luke ut potensielle trykkfeil). Altså, filen importeres ikke daglig, men vi bruker informasjonen der for å sette opp Cerebrumkonstantene som beskriver stillingstypene:
- Nummeret på stillingstypen, 8 siffer. Dette er bare et magisk tall. Det er rundt 400+ av slike som er registrert i de forskjellige SAP-instansene. Av og til kommer det nye, og da må vi lage nye konstantobjekter for de nye kodene i Cerebrum.
- Tekstlig beskrivelse, 40 tegn. Selv om det aldri var lovet, ser alle likedan ut: først den 4-sifrede statlige lønnskoden, så en tekstlig beskrivelse.
Denne filen brukes primært under utrullingen av Cerebrum for å definere de rette konstantobjektene. Foreløpig har hver institusjon sin, men det kan godt hende alle kan dele på den samme filen.
Den 4-sifrede statlige koden bruker vi for å grupper tilsettingene i vitenskapelige og teknisk-administrative. Dette gjøres i det man definerer Constant-objektet som beskriver hver stillingstype.
2.9 feide_utvalg.txt
Inneholder listen over utvalg som finnes og hvor folk kan ha verv. Brukes under utrulling av Cerebrum for å definere de rette konstantene. Ellers er ikke i daglig bruk:
- Utvalgsnummer, 4 tegn. Nettopp det.
- Utvalgsnavn, 40 tegn. Tekstlig beskrivelse.
3 Cerebrum-import
Cerebrum støtter:
- Oppdatering av organisasjonsstrukturen basert på filene. Dette må gjøres i kombinasjon med organisasjonsstrukturen som ligger i FS.
- Oppretting/oppdatering av data om personer i Cerebrum basert på filene.
- Oppdatering av person-tilknytninger basert på filene.
3.1 Import av stedkoder
SAP er for mange instanser den autoritative kilden når det gjelder informasjon knyttet til de ansatte. Den autoritative kilden for OU-informasjon og struktur kan, for mange instanser, være FS. Siden SAP og FS opererer med de samme OU'ene, og SAP bruker egen mekanisme for å identifisere OU'ene, må man ha et overbygg for å kunne oversette SAP sine OU id'er til FS (stedkode). Dette gjøres av institusjonen som har SAP-løsningen via fs.sted-tabellen i FS. fs.sted.stedkode_konv må inneholde en tekst på formen "AAAAAAAA-BBBB", der AAAAAAAA er et internt SAP-tall, og BBBB er forretningsområdekode. Denne informasjonen brukes for å populere de rette tabellene i Cerebrum og gjør det mulig å oversette OU'ene som kommer fra SAP til OU'ene slik de er registrert i Cerebrum. Jobben som oppretter disse oversettelsene går hver dag, i likhet med jobbene som prosesserer de tre filene listet over.
For å knytte en enhet i SAP sammen med en stedkode i FS:
- Hent ut identifikatoren for enheten fra SAP, på formen "AAAAAAAA-BBBB".
- I FS, gå til stedkoden som er samme enhet. Legg til SAP-identifikatoren i feltet stedkode_konv.
Ved neste import i Cerebrum skal da disse to enhetene bli knyttet sammen. Organisasjonsstrukturen blir da samlet, og personer fra SAP og FS vil kunne vere registrert på samme enheter.
3.2 Import av personer
Cerebrum leser inn alle personer som blir ansett som aktive i følge SAP-filene, og oppretter og/eller oppdaterer personene i Cerebrum.
Hva som skjer i Cerebrum sin import av personer fra SAP:
Hent ut hver linje fra feide_persondata.txt
Forkast alle ugyldige linjer og der visse kriterier er oppfylt:
- Forretningsområdekoden er satt til 9999. Dette gjelder bare for instanser som bruker FOK.
- Personen er utgått ved at fratredelsesdato er passert.
Sjekk person-identifikatorer:
Sjekk om en eksisterende person allerede er registrert i Cerebrum med tilsvarende fødselsnummer og/eller ansattnummer. I så fall er det denne personen som vil bli oppdatert, ellers opprettes en ny person.
Det registreres som en feil, og personen vil ikke bli importert, dersom det er fare for identitetsforveksling. Dette kan for eksempel skje dersom fødselsnummer og ansattnummer er tilknyttet to ulike personer.
Om det er en eksisterende person, identifisert med ansattnummer, men Cerebrum sitt fødselsnummer er utdatert, oppdateres dette til det som SAP mener er riktig.
Fødselsnummeret må vere gyldig. Sjekksummen må vere gyldig, datoen må eksistere, og personnummeret kan ikke vere på formen 00?00, for eksempel 00100 og 00200, da dette ikke er unike fødselsnummer, og brukes ofte på personer som ikke skal vere aktive.
Opprett og/eller oppdater personen sine data i Cerebrum for kjønn, fødselsdato, fødselsnummer og ansattnummer.
Oppdater personen sitt fornavn, etternavn og initialer. Navn registreres per kildesystem i Cerebrum, så vi overskriver bare evt. tidligere navn registrert fra SAP.
Vi sletter ikke navnene til personer som ikke lenger importeres.
Oppdater personen sin kontaktinformasjon, som telefonnummer, privat telefonnummer, faxnummer, mobilnummer og privat mobilnummer.
Vi sletter mobil og privatmobil fra Cerebrum dersom dette ikke lenger er registrert i SAP-filen. Vanlige telefonnummer slettes ikke per i dag, av historiske årsaker.
Oppdater personen sin kontoradresse, altså adressen til bygg, med romnummer. Informasjonen slettes fra Cerebrum dersom det ikke lenger er registrert i SAP-filen for personen.
Denne funksjonaliteten avhenger av om Cerebrum er satt opp for dette, da det er ulikt per instans om dette brukes.
Oppdater personen sin postadresse. Vi sletter ikke denne informasjonen fra Cerebrum.
Dersom personen er registrert som reservert legges personen til i gruppen for reservasjoner. Vanligvis er dette gruppen SAP-elektroniske-reservasjoner.
Oppdater personen sin arbeidstittel fra feide_persondata.txt. Arbeidstittelen slettes fra Cerebrum hvis den ikke lenger er registrert i SAP-filen.
Merk at Cerebrum ikke importerer personlige titler fra SAP-filene.
Lagre personen sin medarbeidergruppe og medarbeiderundergruppe. Dette brukes bare dersom instansen er satt opp for det, da det behandles ulikt per instans.
3.2.1 Ignorering av personer
SAP-filene kan inneholde flere personer enn de som skal til Cerebrum for IT-tilgang. Det er ulike måter Cerebrum kan ignorere personer fra SAP:
- Forretningsområdekode 9999. Dette er/var en generell regel for å ekskludere personer fra import.
- MG og MUG. Cerebrum har støtte for å ignorere personer som er registrert med spesifikke MG/MUG-koder. Cerebrum må evt. få en liste over hvilke koder dette gjelder før dette tar effekt.
4 SAP-modulbeskrivelse
Da SAP-løsningen skulle rulles ut ved UiA, ble det besluttet å lagre noe av informasjonen fra SAP i Cerebrum. Til det formål ble det laget egen modul, mod_sap, som tok vare på de nødvendige databitene.
Modulen består av en liten utvidelse av databaseskjemaet vårt (noen kodetabeller samt tabeller for å ta være på person/OU-informasjon), et koderammeverk (en del Constant-objekter) og utvidelser av grensesnittet til Person- og OU-klassene i Cerebrum for å få tilgang til disse data. Når CLASS_PERSON og CLASS_OU inneholder de rette klassene, skal funksjonaliteten være tilgjengelig.
4.1 DB-skjema
DB-skjema er illustrert i figuren under.
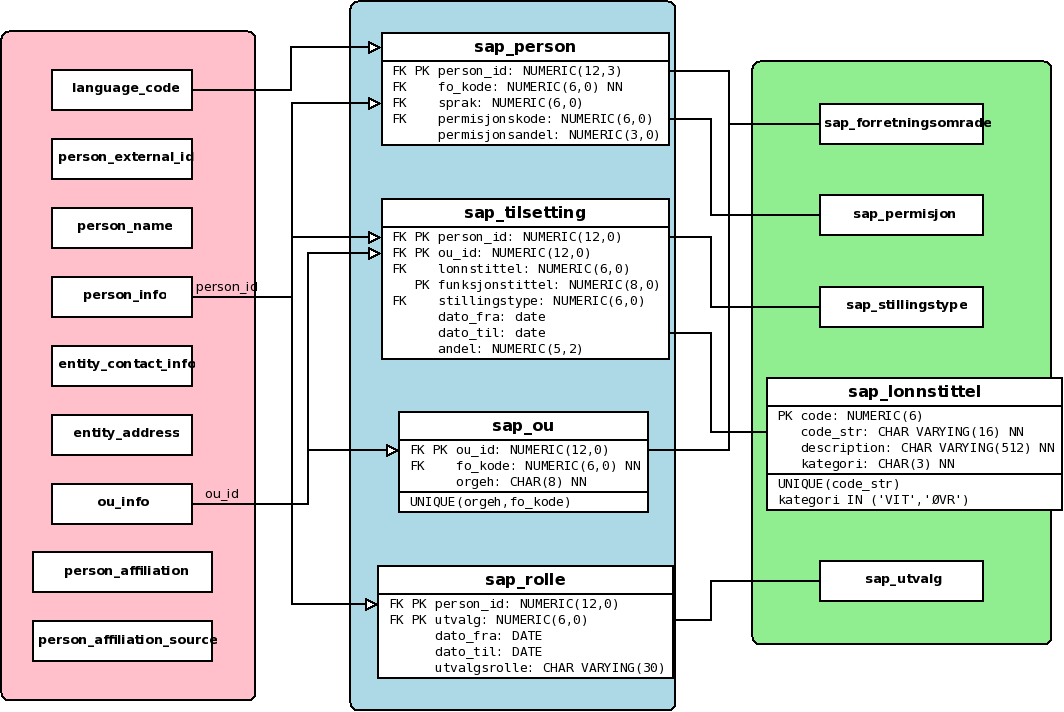
Tabellene med rosa bakgrunn er de som allerede finnes i Cerebrum. De brukes til:
- language_code brukes for å lagre språkkodene, siden vi har planer om å registrere foretrukket språk for hver person. Dette gjøres egentlig ikke per i dag (siden language_code ikke er populert), men siden skranken eksisterer, kan det potensielt innføres en dag. Behovet for foretrukket språk har ikke dukket opp noen steder, men muligheten er iallfall der.
- person_external_id brukes for å lagre SAP-ansattnummer og fødselsnummer fra SAP.
- person_name brukes for å lagre navn/tittel-informasjonen fra SAP.
- person_info.person_id er identifikatoren for personer. Når nye personer dukker fra SAP, må naturligvis person_info populeres.
- entity_contact_info brukes for å populere telefon/faksnumre fra SAP.
- entity_address brukes til lagring av adresseinformasjon for personer.
- ou_info.ou_id brukes internt for å referere til OU'er (som er nødvendig for tilsetting, og mapping av SAP sin OU-id).
- person_affiliation tabellene brukes for å registrere affiliations som stammer fra SAP.
Tabellene med grønn bakgrunn er mod_sap sine egne kodetabeller. De har alle sammen det "klassiske" kodetabellutseendet fra cerebrum med 3 kolonner: "code" for en automatisk tilordnet numerisk verdi; "code_str" for å kunne mappe SAP sitt kodenummer til Cerebrum sitt intern; og "description" for å fortelle mennesker hva koden gjør. sap_lonnstittel er litt annerledes, da vi i tillegg til disse 3 tar vare på kategorien til tilsettingen som sap_lonnstittel-radene beskriver (vitenskapelig og teknisk-administrativ). (Det burde ha vært en skranke akkurat der, selv om den ikke finnes i dag (2007-10-19).)
Tabellene med lyseblå bakgrunn er alle de andre tabellene fra mod_sap. De inneholder nemlig SAP-spesifikk ansattinformasjon:
- I sap_person knytter vi litt ymse SAP-data til personer. Ingenting av dette er aktivt brukt i dag (tabellen blir populert, men det er omtrent det som skjer).
- I sap_tilsetting registrerer vi tilsettingsinformasjonen. Heller ikke denne tabellen blir aktivt brukt i dag (dog, man kan fx. tildele SAP-affiliations basert på den (Utrolig nok tildeles affiliations basert på filen (feide_persti.txt), heller enn en verifisert/konsistent tabell i mod_sap. IVR 2007-10-19 FIXME: fixit!)
- sap_ou brukes for å kunne oversette SAP OU id'er til ou_id som brukes overalt i Cerebrum
- sap_rolle populeres med roller/verv personer har i forskjellige utvalg. Vi har per i dag (2007-10-19) ingen instanser der det kommer data om dette, så funkajonaliteten er ikke en gang skikkelig testet.
Tabellene populeres vanligvis en gang i døgnet, sammen med de andre nattlige jobbene.
4.2 Cerebrum-API
Det kreves noen utvidelser av Cerebrum for å få tilgang til de forskjellige tabellene. Alle disse finnes i Cerebrum/modules/no/hia/mod_sap.py. Det er gjerne en mixin til Person og en til OU. I tillegg har vi naturligvis de nødvendige konstantobjektene for å "få tak i" innholdet i diverse konstanttabeller.
PersonSAPMixin kan føyes til CLASS_PERSON for å få tilgang til mod_sap sine utvidelser som gir adgang til sap_person/tilsetting/rolle-tabellene. OUSAPMixin kan føyes til CLASS_OU for å få tilgang til sap_ou-tabellen fra Cerebrum.
Det kan tenkes at Cerebrum-APIet (såvel som db-skjema, egentlig) burde revideres. Vi kan prøve å holde oss til de eksisterende tabellene i Cerebrum i den grad det går, og heller prøve å registrere kun den informasjonen som faktisk vil bli brukt videre. Essensielt trenger vi konstanttabellene og mappingen mellom løpenummer+forr.omr.kode og ou_id.
4.3 Populering
Når det gjelder populeringen av tabellene knyttet til mod_sap, skjer dette på forskjellige tidspunkter.
Under utrulling av Cerebruminnstansen, må man definere de nødvendige konstantene. Dette skjer gjerne i Cerebrum/modules/no/<institusjon>/mod_sap_codes.py. Klassene for de forskjellige konstanttypene er definert i Cerebrum/modules/no/Constants.py. Deretter sørger man for at CLASS_CONSTANTS inneholder de rette klassene, og kan kjøre makedb.py. Databasen vil inneholde de nødvendige konstantene. Skulle det oppstå behov for nye konstanter, er det bare å utvide mod_sap_codes.py og kjøre makedb.py --only-insert-codes på nytt.
Daglig kjøres det en rekke jobber som populerer/oppdaterer andre tabeller i Cerebrum (og i mod_sap spesifikt):
- import_SAP_OU_id.py populerer sap_ou; altså mapper SAP sitt <løpenummer, forr.omr.kode>-par til en passende ou_id. Til dette trenger man en forbindelse til FS-instansen for den aktuelle&&& institusjonen. (Egentlig trenger vi kun stedkode samt <løpenummer, forr.omr.kode>. Hvor de kommer fra er mindre vesentlig. Man kan fx. trekke data rett fra en fil, heller enn direkte fra FS-instansen).
- import_SAP_person.py populerer sap_person samt en rekke tabeller i Cerebrum core med data om ansatte. Nye ansatte, endringer i navn, kontaktinformasjon og slikt skjer i denne fasen.
- import_SAP_person_tilsetting.py populerer utelukkende sap_tilsetting tabellen.
- import_SAP_person_utvalg.py populerer tilsvarende kun sap_rolle-tabellen.
- process_SAP_affiliations.py populerer person_affiliation* tabellene med ansatt og tilknyttet affiliations avledet fra siste tilgjengelige feide_persti.txt. Siden oppdateringen fjerner ukurrante&&& affiliations såvel som å legge til nye, er det viktig å ikke gi denne jobben en tom fil.